
[ad_1]
Ever since the current craze for AI-generated everything took hold, I’ve wondered: what will happen when the world is so full of AI-generated stuff (text, software, pictures, music) that our training sets for AI are dominated by content created by AI. We already see hints of that on GitHub: in February 2023, GitHub said that 46% of all the code checked in was written by Copilot. That’s good for the business, but what does that mean for future generations of Copilot? At some point in the near future, new models will be trained on code that they have written. The same is true for every other generative AI application: DALL-E 4 will be trained on data that includes images generated by DALL-E 3, Stable Diffusion, Midjourney, and others; GPT-5 will be trained on a set of texts that includes text generated by GPT-4; and so on. This is unavoidable. What does this mean for the quality of the output they generate? Will that quality improve or will it suffer?
I’m not the only person wondering about this. At least one research group has experimented with training a generative model on content generated by generative AI, and has found that the output, over successive generations, was more tightly constrained, and less likely to be original or unique. Generative AI output became more like itself over time, with less variation. They reported their results in “The Curse of Recursion,” a paper that’s well worth reading. (Andrew Ng’s newsletter has an excellent summary of this result.)

Learn faster. Dig deeper. See farther.
I don’t have the resources to recursively train large models, but I thought of a simple experiment that might be analogous. What would happen if you took a list of numbers, computed their mean and standard deviation, used those to generate a new list, and did that repeatedly? This experiment only requires simple statistics—no AI.
Although it doesn’t use AI, this experiment might still demonstrate how a model could collapse when trained on data it produced. In many respects, a generative model is a correlation engine. Given a prompt, it generates the word most likely to come next, then the word mostly to come after that, and so on. If the words “To be” pop out, the next word is reasonably likely to be “or”; the next word after that is even more likely to be “not”; and so on. The model’s predictions are, more or less, correlations: what word is most strongly correlated with what came before? If we train a new AI on its output, and repeat the process, what is the result? Do we end up with more variation, or less?
To answer these questions, I wrote a Python program that generated a long list of random numbers (1,000 elements) according to the Gaussian distribution with mean 0 and standard deviation 1. I took the mean and standard deviation of that list, and use those to generate another list of random numbers. I iterated 1,000 times, then recorded the final mean and standard deviation. This result was suggestive—the standard deviation of the final vector was almost always much smaller than the initial value of 1. But it varied widely, so I decided to perform the experiment (1,000 iterations) 1,000 times, and average the final standard deviation from each experiment. (1,000 experiments is overkill; 100 or even 10 will show similar results.)
When I did this, the standard deviation of the list gravitated (I won’t say “converged”) to roughly 0.45; although it still varied, it was almost always between 0.4 and 0.5. (I also computed the standard deviation of the standard deviations, though this wasn’t as interesting or suggestive.) This result was remarkable; my intuition told me that the standard deviation wouldn’t collapse. I expected it to stay close to 1, and the experiment would serve no purpose other than exercising my laptop’s fan. But with this initial result in hand, I couldn’t help going further. I increased the number of iterations again and again. As the number of iterations increased, the standard deviation of the final list got smaller and smaller, dropping to .0004 at 10,000 iterations.
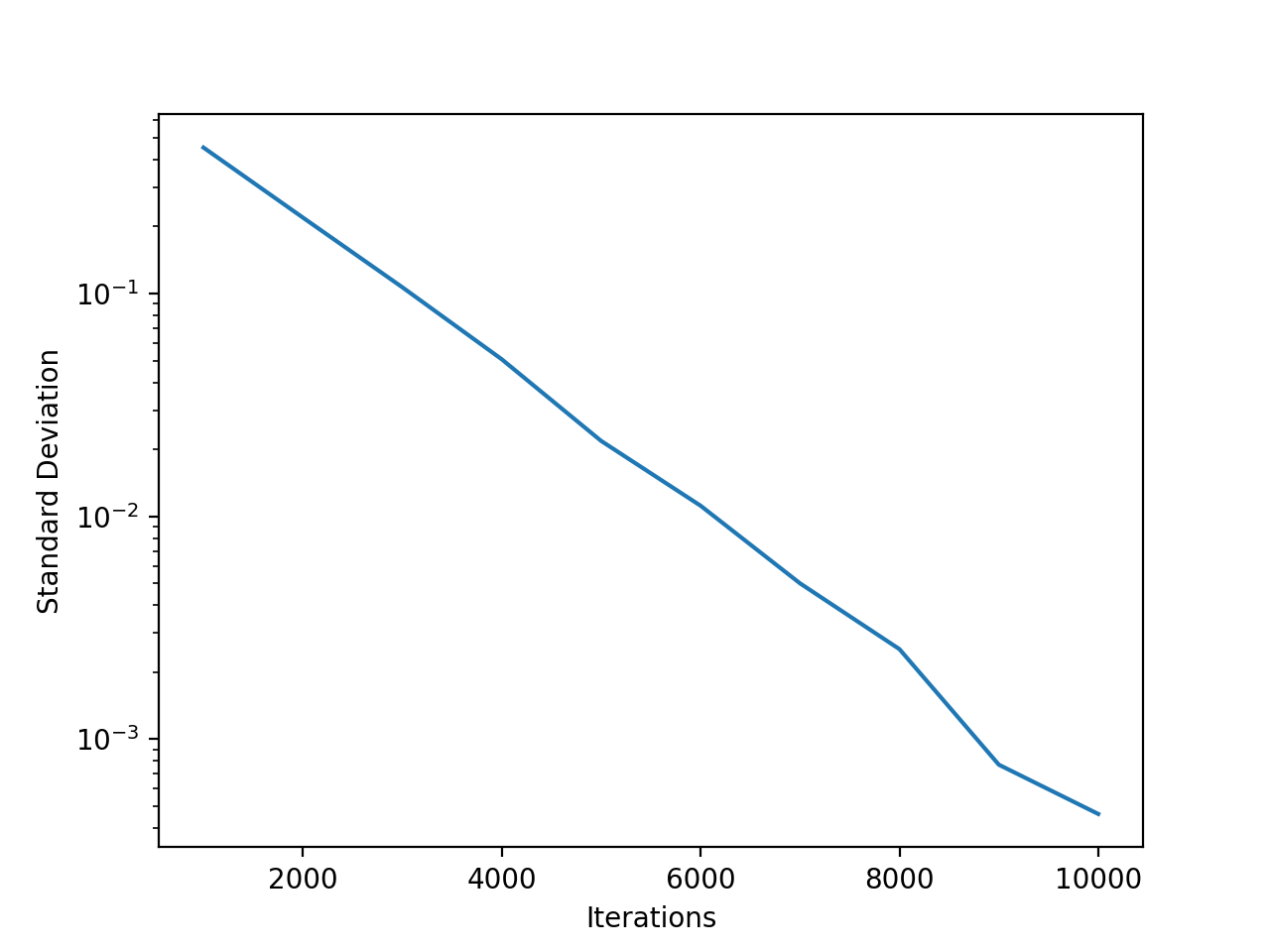
I think I know why. (It’s very likely that a real statistician would look at this problem and say “It’s an obvious consequence of the law of large numbers.”) If you look at the standard deviations one iteration at a time, there’s a lot a variance. We generate the first list with a standard deviation of one, but when computing the standard deviation of that data, we’re likely to get a standard deviation of 1.1 or .9 or almost anything else. When you repeat the process many times, the standard deviations less than one, although they aren’t more likely, dominate. They shrink the “tail” of the distribution. When you generate a list of numbers with a standard deviation of 0.9, you’re much less likely to get a list with a standard deviation of 1.1—and more likely to get a standard deviation of 0.8. Once the tail of the distribution starts to disappear, it’s very unlikely to grow back.
What does this mean, if anything?
My experiment shows that if you feed the output of a random process back into its input, standard deviation collapses. This is exactly what the authors of “The Curse of Recursion” described when working directly with generative AI: “the tails of the distribution disappeared,” almost completely. My experiment provides a simplified way of thinking about collapse, and demonstrates that model collapse is something we should expect.
Model collapse presents AI development with a serious problem. On the surface, preventing it is easy: just exclude AI-generated data from training sets. But that’s not possible, at least now because tools for detecting AI-generated content have proven inaccurate. Watermarking might help, although watermarking brings its own set of problems, including whether developers of generative AI will implement it. Difficult as eliminating AI-generated content might be, collecting human-generated content could become an equally significant problem. If AI-generated content displaces human-generated content, quality human-generated content could be hard to find.
If that’s so, then the future of generative AI may be bleak. As the training data becomes ever more dominated by AI-generated output, its ability to surprise and delight will diminish. It will become predictable, dull, boring, and probably no less likely to “hallucinate” than it is now. To be unpredictable, interesting, and creative, we still need ourselves.
[ad_2]