{kind=link}
Adding an index to a database is one of those little joys in life. A query takes 10 seconds, you add a good index, and boom…10 milliseconds! Customers are happy, manager is happy, database is happy (according to its CPU graph at least). However, managing indexes gets old quickly. More indexes means writes are slower. There is always another query creeping up on the latency graph. Imagine the sum total of human time spent playing whack-a-mole with database indexes. Even worse, imagine how much of our daily interaction with technology is impacted by slow, unindexed queries.
Our Solution is a Converged Index™
Rockset is approaching this problem with a radical solution: build indexes on all columns. One of the design goals of Rockset is to absolutely minimize the amount of configuration the user needs to do. Creating indexes is a configuration; it has to go. We call our approach a Converged Index. A Converged Index allows analytical queries on large datasets to return in milliseconds. Using Rockset, you will never have to manually define or create your indexes or update them over time. This is Rockset’s secret sauce that makes all your queries so fast and efficient.
Before we dive into the technical details, let me share some background on two types of indexing we build upon: columnar indexing and search indexing.
Columnar Indexing
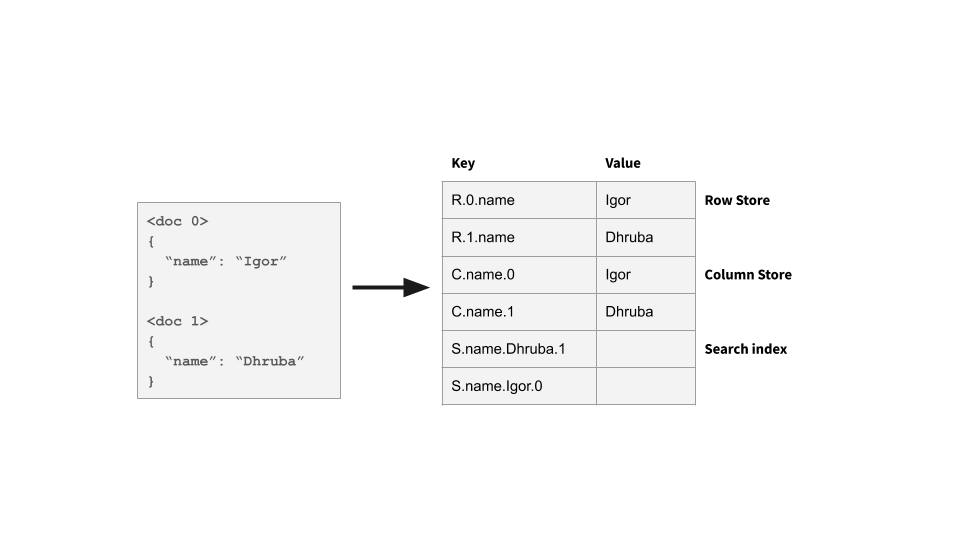
In the beginning, there was row-oriented storage, where a single row is stored contiguously on the storage media. Fetching a single row is fast — a single IO. However, in some cases a database table might contain a huge number of columns, while a query only touches a small subset. For those kinds of queries, column-oriented storage works better.
In column-oriented storage, we store all values for a particular column contiguously on storage. A query can efficiently fetch exactly the columns that it needs, which makes it great for analytical queries over wide datasets. Additionally, column-oriented storage has better compression ratios. Values within one column are usually similar to each other, and similar values compress really well when stored together. There are some advanced techniques that make compression even better, like dictionary compression or run-length encoding. It should be no surprise that column-oriented storage is used by some of the most successful data warehousing solutions, such as Snowflake, Amazon Redshift, Google’s BigQuery, or Vertica.

Search Indexing
Search indexing is a technique that makes search-like queries fast. In search indexing for each (column, value) pair, we store the list of documents for which column = value, called posting lists. Any query with a simple predicate can quickly fetch a list of documents satisfying that predicate. By keeping the posting lists sorted, we can intersect the lists or merge them to satisfy conjunction or disjunction of predicates, respectively. Search indexing is used in systems like Elasticsearch and Apache Solr, both based on the Apache Lucene library.

Converged Index: Row + Column + Search
At Rockset, we store every column of every document in a Converged Index that incorporates aspects of a row-based store, column-based store and a search index.

That might sound like it could require more overhead than creating indexes as they are needed, but there is big gain from our approach. Here are two main reasons:
- A Converged Index requires more space on disk, but our queries are faster. In simple terms, we trade off storage for CPU. However, more importantly, we trade off hardware for human time. Humans no longer need to configure indexes, and humans no longer need to wait on slow queries. The Converged Index is the most efficient way to organize data in a way that reduces overhead and optimizes your data for query performance.
- As any experienced database user knows, as you add more indexes, writes become heavier. A single document update now needs to update many indexes, causing many random database writes. In traditional storage based on B-trees, random writes to the database translate to random writes on storage. At Rockset, we use LSM trees instead of B-trees. LSM trees are optimized for writes because they turn random writes to database into sequential writes on storage. You can learn more in this great article: Algorithms Behind Modern Storage Systems. We use RocksDB’s LSM tree implementation and we have internally benchmarked hundreds of MB per second writes in a distributed setting.
We have all these indexes, but how do we pick the best one for our query? We built a custom SQL query optimizer that analyzes every query and decides on the execution plan. For example, consider the following queries:
Query 1
SELECT *
FROM search_logs
WHERE keyword = ‘rockset’
AND locale = ‘en’
The optimizer will use the database statistics to determine that query needs to fetch a tiny fraction of the database. It will decide to answer the query with the search index.
Query 2
SELECT keyword, count(*) c
FROM search_logs
GROUP BY keyword
ORDER BY c DESC
There are no filters in this query; the optimizer will choose to use the column store. Because the column store keeps columns separate, this query only needs to scan values for column keywords, yielding a much faster performance than a traditional row store.
It is especially satisfying to see delighted customers who are not used to fast queries out of the box get started with zero configuration. However, our work is not done. We continue to improve our indexing and query performance, and have some exciting ideas on using custom compression for both columnar store and search indexing. If you are curious about Rockset’s performance on your workload, you can sign up for a free Rockset account. We are also hiring.
P.S. If you want to learn more about how we built a Converged Index, check out our presentation from Strata San Francisco 2019.
Embedded content: https://youtu.be/XsDXAecUIb4
Note: A Converged Index creates indexes of information for others using information technology. It is used in database management software which is not field specific and can be used by companies in all fields.