{kind=link}
In this blog post I compare options for real-time analytics on DynamoDB – Elasticsearch, Athena, and Spark – in terms of ease of setup, maintenance, query capability, latency. There is limited support for SQL analytics with some of these options. I also evaluate which use cases each of them are best suited for.
Developers often have a need to serve fast analytical queries over data in Amazon DynamoDB. Real-time analytics use cases for DynamoDB include dashboards to enable live views of the business and progress to more complex application features such as personalization and real-time user feedback. However, as an operational database optimized for transaction processing, DynamoDB is not well-suited to delivering real-time analytics. At Rockset, we recently added support for creating collections that pull data from Amazon DynamoDB – which basically means you can run fast SQL on DynamoDB tables without any ETL. As part of this effort, I spent a significant amount of time evaluating the methods developers use to perform analytics on DynamoDB data and understanding which method is best suited based on the use case and found that Elasticsearch, Athena, and Spark each have their own pros and cons.
DynamoDB has been one of the most popular NoSQL databases in the cloud since its introduction in 2012. It is central to many modern applications in ad tech, gaming, IoT, and financial services. As opposed to a traditional RDBMS like PostgreSQL, DynamoDB scales horizontally, obviating the need for careful capacity planning, resharding, and database maintenance. While NoSQL databases like DynamoDB generally have excellent scaling characteristics, they support only a limited set of operations that are focused on online transaction processing. This makes it difficult to develop analytics directly on them.
In order to support analytical queries, developers typically use a multitude of different systems in conjunction with DynamoDB. In the following sections, we will explore a few of these approaches and compare them along the axes of ease of setup, maintenance, query capability, latency, and use cases they fit well.
If you want to support analytical queries without encountering prohibitive scan costs, you can leverage secondary indexes in DynamoDB which supports a limited type of queries. However for a majority of analytic use cases, it is cost effective to export the data from DynamoDB into a different system like Elasticsearch, Athena, Spark, Rockset as described below, since they allow you to query with higher fidelity.
DynamoDB + Glue + S3 + Athena

One approach is to extract, transform, and load the data from DynamoDB into Amazon S3, and then use a service like Amazon Athena to run queries over it. We can use AWS Glue to perform the ETL process and create a complete copy of the DynamoDB table in S3.


Amazon Athena expects to be presented with a schema in order to be able to run SQL queries on data in S3. DynamoDB, being a NoSQL store, imposes no fixed schema on the documents stored. Therefore, we need to extract the data and compute a schema based on the data types observed in the DynamoDB table. AWS Glue is a fully managed ETL service that lets us do both. We can use two functionalities provided by AWS Glue—Crawler and ETL jobs. Crawler is a service that connects to a datastore (such as DynamoDB) and scans through the data to determine the schema. Separately, a Glue ETL Apache Spark job can scan and dump the contents of any DynamoDB table into S3 in Parquet format. This ETL job can take minutes to hours to run depending on the size of the DynamoDB table and the read bandwidth on the DynamoDB table. Once both these processes have completed, we can fire up Amazon Athena and run queries on the data in DynamoDB.

This entire process does not require provisioning any servers or capacity, or managing infrastructure, which is advantageous. It can be automated fairly easily using Glue Triggers to run on a schedule. Amazon Athena can be connected to a dashboard such as Amazon QuickSight that can be used for exploratory analysis and reporting. Athena is based on Apache Presto which supports querying nested fields, objects and arrays within JSON.
A major disadvantage of this method is that the data cannot be queried in real time or near real time. Dumping all of DynamoDB’s contents can take minutes to hours before it is available for running analytical queries. There is no incremental computation that keeps the two in sync—every load is an entirely new sync. This also means the data that is being operated on in Amazon Athena could be several hours out of date.
The ETL process can also lose information if our DynamoDB data contains fields that have mixed types across different items. Field types are inferred when Glue crawls DynamoDB, and the dominant type detected will be assigned as the type of a column. Although there is JSON support in Athena, it requires some DDL setup and management to turn the nested fields into columns for running queries over them effectively. There can also be some effort required for maintenance of the sync between DynamoDB, Glue, and Athena when the structure of data in DynamoDB changes.
Advantages
- All components are “serverless” and require no provisioning of infrastructure
- Easy to automate ETL pipeline
Disadvantages
- High end-to-end data latency of several hours, which means stale data
- Query latency varies between tens of seconds to minutes
- Schema enforcement can lose information with mixed types
- ETL process can require maintenance from time to time if structure of data in source changes
This approach can work well for those dashboards and analytics that do not require querying the latest data, but instead can use a slightly older snapshot. Amazon Athena’s SQL query latencies of seconds to minutes, coupled with the large end-to-end latency of the ETL process, makes this approach unsuitable for building operational applications or real-time dashboards over DynamoDB.

DynamoDB + Hive/Spark

An alternative approach to unloading the entire DynamoDB table into S3 is to run queries over it directly, using DynamoDB’s Hive integration. The Hive integration allows querying the data in DynamoDB directly using HiveQL, a SQL-like language that can express analytical queries. We can do this by setting up an Amazon EMR cluster with Hive installed.

Once our cluster is set up, we can log into our master node and specify an external table in Hive pointing to the DynamoDB table that we’re looking to query. It requires that we create this external table with a particular schema definition for the data types. One caveat is that Hive is read intensive, and the DynamoDB table must be set up with sufficient read throughput to avoid starving other applications that are being served from it.
hive> CREATE EXTERNAL TABLE twitter(hashtags string, language string, text string)
> STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
> TBLPROPERTIES (
> "dynamodb.table.name" = "foxish-test-table",
> "dynamodb.column.mapping" = "hashtags:hashtags,language:language,text:text"
> );
WARNING: Configured write throughput of the dynamodb table foxish-test-table is less than the cluster map capacity. ClusterMapCapacity: 10 WriteThroughput: 5
WARNING: Writes to this table might result in a write outage on the table.
OK
Time taken: 2.567 seconds
hive> show tables;
OK
twitter
Time taken: 0.135 seconds, Fetched: 1 row(s)
hive> select hashtags, language from twitter limit 10;
OK
music km
music in
music th
music ja
music es
music en
music en
music en
music en
music ja
music en
Time taken: 0.197 seconds, Fetched: 10 row(s)
This approach gives us more up-to-date results and operates on the DynamoDB table directly rather than building a separate snapshot. The same mechanism we saw in the previous section applies in that we need to provide a schema that we compute using a service like AWS Glue Crawler. Once the external table is set up with the correct schema, we can run interactive queries on the DynamoDB table written in HiveQL. In a very similar manner, one can also connect Apache Spark to a DynamoDB table using a connector for running Spark SQL queries. The advantage of these approaches is that they are capable of operating on up-to-date DynamoDB data.
A disadvantage of the approach is that it can take several seconds to minutes to compute results, which makes it less than ideal for real-time use cases. Incorporating new updates as they occur to the underlying data typically requires another full scan. The scan operations on DynamoDB can be expensive. Running these analytical queries powered by table scans frequently can also adversely impact the production workload that is using DynamoDB. Therefore, it is difficult to power operational applications built directly on these queries.
In order to serve applications, we may need to store the results from queries run using Hive/Spark into a relational database like PostgreSQL, which adds another component to maintain, administer, and manage. This approach also departs from the “serverless” paradigm that we used in previous approaches as it requires managing some infrastructure, i.e. EC2 instances for EMR and possibly an installation of PostgreSQL as well.
Advantages
- Queries over latest data in DynamoDB
- Requires no ETL/pre-processing other than specifying a schema
Disadvantages
- Schema enforcement can lose information when fields have mixed types
- EMR cluster requires some administration and infrastructure management
- Queries over the latest data involves scans and are expensive
- Query latency varies between tens of seconds to minutes directly on Hive/Spark
- Security and performance implications of running analytical queries on an operational database
This approach can work well for some kinds of dashboards and analytics that do not have tight latency requirements and where it’s not cost prohibitive to scan over the entire DynamoDB table for ad hoc interactive queries. However, for real-time analytics, we need a way to run a wide range of analytical queries without expensive full table scans or snapshots that quickly fall out of date.
DynamoDB + AWS Lambda + Elasticsearch

Another approach to building a secondary index over our data is to use DynamoDB with Elasticsearch. Elasticsearch can be set up on AWS using Amazon Elasticsearch Service, which we can use to provision and configure nodes according to the size of our indexes, replication, and other requirements. A managed cluster requires some operations to upgrade, secure, and keep performant, but less so than running it entirely by oneself on EC2 instances.

As the approach using the Logstash Plugin for Amazon DynamoDB is unsupported and rather difficult to set up, we can instead stream writes from DynamoDB into Elasticsearch using DynamoDB Streams and an AWS Lambda function. This approach requires us to perform two separate steps:
- We first create a lambda function that is invoked on the DynamoDB stream to post each update as it occurs in DynamoDB into Elasticsearch.
- We then create a lambda function (or EC2 instance running a script if it will take longer than the lambda execution timeout) to post all the existing contents of DynamoDB into Elasticsearch.
We must write and wire up both of these lambda functions with the correct permissions in order to ensure that we do not miss any writes into our tables. When they are set up along with required monitoring, we can receive documents in Elasticsearch from DynamoDB and can use Elasticsearch to run analytical queries on the data.
The advantage of this approach is that Elasticsearch supports full-text indexing and several types of analytical queries. Elasticsearch supports clients in various languages and tools like Kibana for visualization that can help quickly build dashboards. When a cluster is configured correctly, query latencies can be tuned for fast analytical queries over data flowing into Elasticsearch.
Disadvantages include that the setup and maintenance cost of the solution can be high. Because lambdas fire when they see an update in the DynamoDB stream, they can have have latency spikes due to cold starts. The setup requires metrics and monitoring to ensure that it is correctly processing events from the DynamoDB stream and able to write into Elasticsearch. It is also not “serverless” in that we pay for provisioned resources as opposed to the resources that we actually use. Even managed Elasticsearch requires dealing with replication, resharding, index growth, and performance tuning of the underlying instances. Functionally, in terms of analytical queries, it lacks support for joins, which are useful for complex analytical queries that involve more than one index.
Advantages
- Full-text search support
- Support for several types of analytical queries
- Can work over the latest data in DynamoDB
Disadvantages
- Requires management and monitoring of infrastructure for ingesting, indexing, replication, and sharding
- Requires separate system to ensure data integrity and consistency between DynamoDB and Elasticsearch
- Scaling is manual and requires provisioning additional infrastructure and operations
- No support for joins between different indexes
This approach can work well when implementing full-text search over the data in DynamoDB and dashboards using Kibana. However, the operations required to tune and maintain an Elasticsearch cluster in production, with tight requirements around latency and data integrity for real-time dashboards and applications, can be challenging.
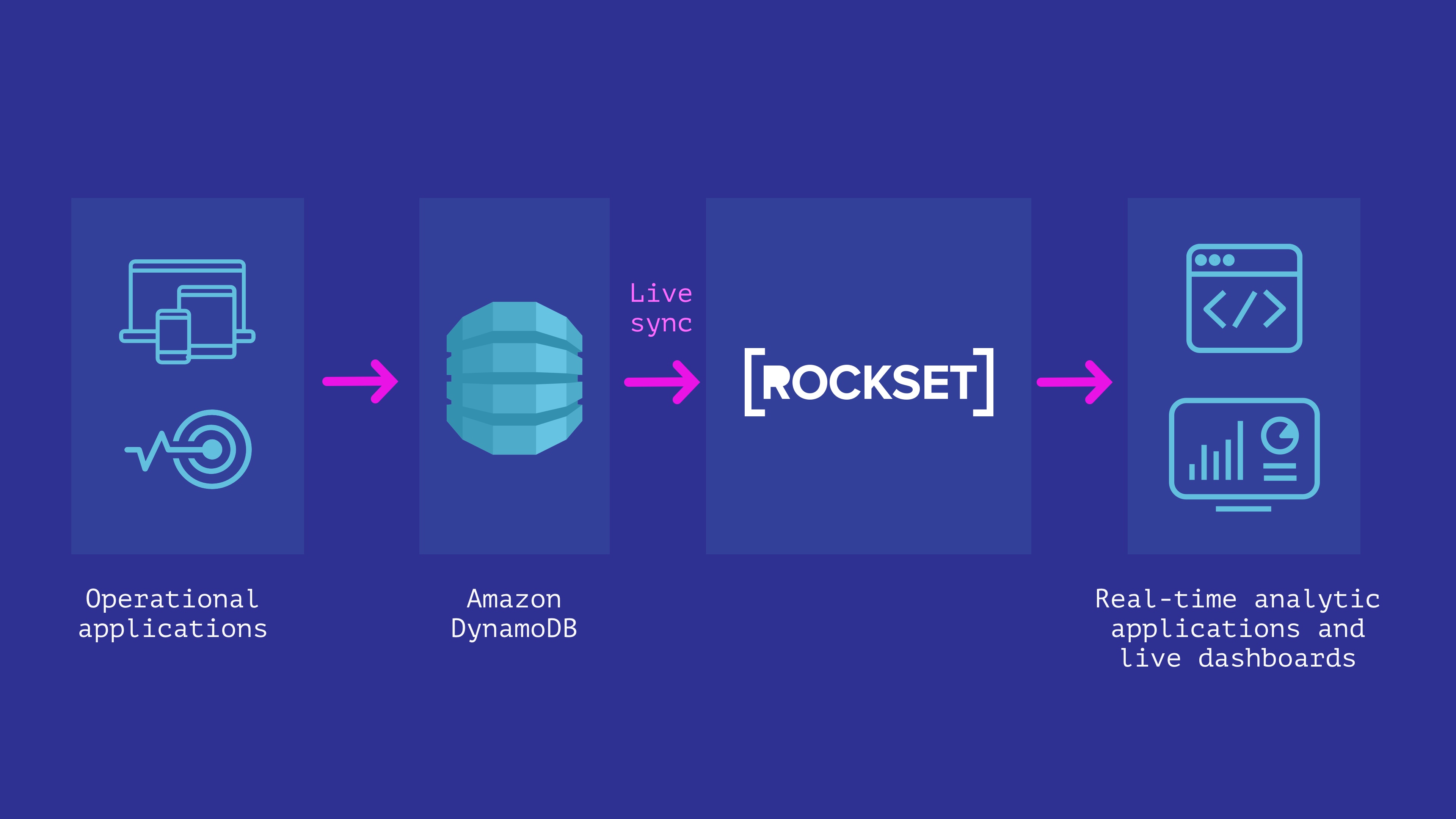
DynamoDB + Rockset

Rockset is a completely managed service for real-time indexing built primarily to support real-time applications with high QPS requirements.
Rockset has a live integration with DynamoDB that can be used to keep data in sync between DynamoDB and Rockset. We can specify the DynamoDB table we want to sync contents from and a Rockset collection that indexes the table. Rockset indexes the contents of the DynamoDB table in a full snapshot and then syncs new changes as they occur. The contents of the Rockset collection are always in sync with the DynamoDB source; no more than a few seconds apart in steady state.

Rockset manages the data integrity and consistency between the DynamoDB table and the Rockset collection automatically by monitoring the state of the stream and providing visibility into the streaming changes from DynamoDB.

Without a schema definition, a Rockset collection can automatically adapt when fields are added/removed, or when the structure/type of the data itself changes in DynamoDB. This is made possible by strong dynamic typing and smart schemas that obviate the need for any additional ETL.
The Rockset collection we sourced from DynamoDB supports SQL for querying and can be easily used to build real-time dashboards using integrations with Tableau, Superset, Redash, etc. It can also be used to serve queries to applications over a REST API or using client libraries in several programming languages. The superset of ANSI SQL that Rockset supports can work natively on deeply nested JSON arrays and objects, and leverage indexes that are automatically built over all fields, to get millisecond latencies on even complex analytical queries.
In addition, Rockset takes care of security, encryption of data, and role-based access control for managing access to it. We can avoid the need for ETL by leveraging mappings we can set up in Rockset to modify the data as it arrives into a collection. We can also optionally manage the lifecycle of the data by setting up retention policies to automatically purge older data. Both data ingestion and query serving are automatically managed, which lets us focus on building and deploying live dashboards and applications while removing the need for infrastructure management and operations.
Rockset is a good fit for real-time analytics on top of operational data stores like DynamoDB for the following reasons.
Summary
- Built to deliver high QPS and serve real-time applications
- Completely serverless. No operations or provisioning of infrastructure or database required
- Live sync between DynamoDB and the Rockset collection, so that they are never more than a few seconds apart
- Monitoring to ensure consistency between DynamoDB and Rockset
- Automatic indexes built over the data enabling low-latency queries
- SQL query serving that can scale to high QPS
- Joins with data from other sources such as Amazon Kinesis, Apache Kafka, Amazon S3, etc.
- Integrations with tools like Tableau, Redash, Superset, and SQL API over REST and using client libraries.
- Features including full-text search, ingest transformations, retention, encryption, and fine-grained access control
We can use Rockset for implementing real-time analytics over the data in DynamoDB without any operational, scaling, or maintenance concerns. This can significantly speed up the development of live dashboards and applications.
If you’d like to build your application on DynamoDB data using Rockset, you can get started for free on here. For a more detailed example of how one can run SQL queries on a DynamoDB table synced into Rockset, check out our blog on running fast SQL on DynamoDB tables.
Other DynamoDB resources: