{kind=link}
In this blog post, I’ll describe how we use RocksDB at Rockset and how we tuned it to get the most performance out of it. I assume that the reader is generally familiar with how Log-Structured Merge tree based storage engines like RocksDB work.
At Rockset, we want our users to be able to continuously ingest their data into Rockset with sub-second write latency and query it in 10s of milliseconds. For this, we need a storage engine that can support both fast online writes and fast reads. RocksDB is a high-performance storage engine that is built to support such workloads. RocksDB is used in production at Facebook, LinkedIn, Uber and many other companies. Projects like MongoRocks, Rocksandra, MyRocks etc. used RocksDB as a storage engine for existing popular databases and have been successful at significantly reducing space amplification and/or write latencies. RocksDB’s key-value model is also most suitable for implementing converged indexing. So we decided to use RocksDB as our storage engine. We are lucky to have significant expertise on RocksDB in our team in the form of our CTO Dhruba Borthakur who founded RocksDB at Facebook. For each input field in an input document, we generate a set of key-value pairs and write them to RocksDB.
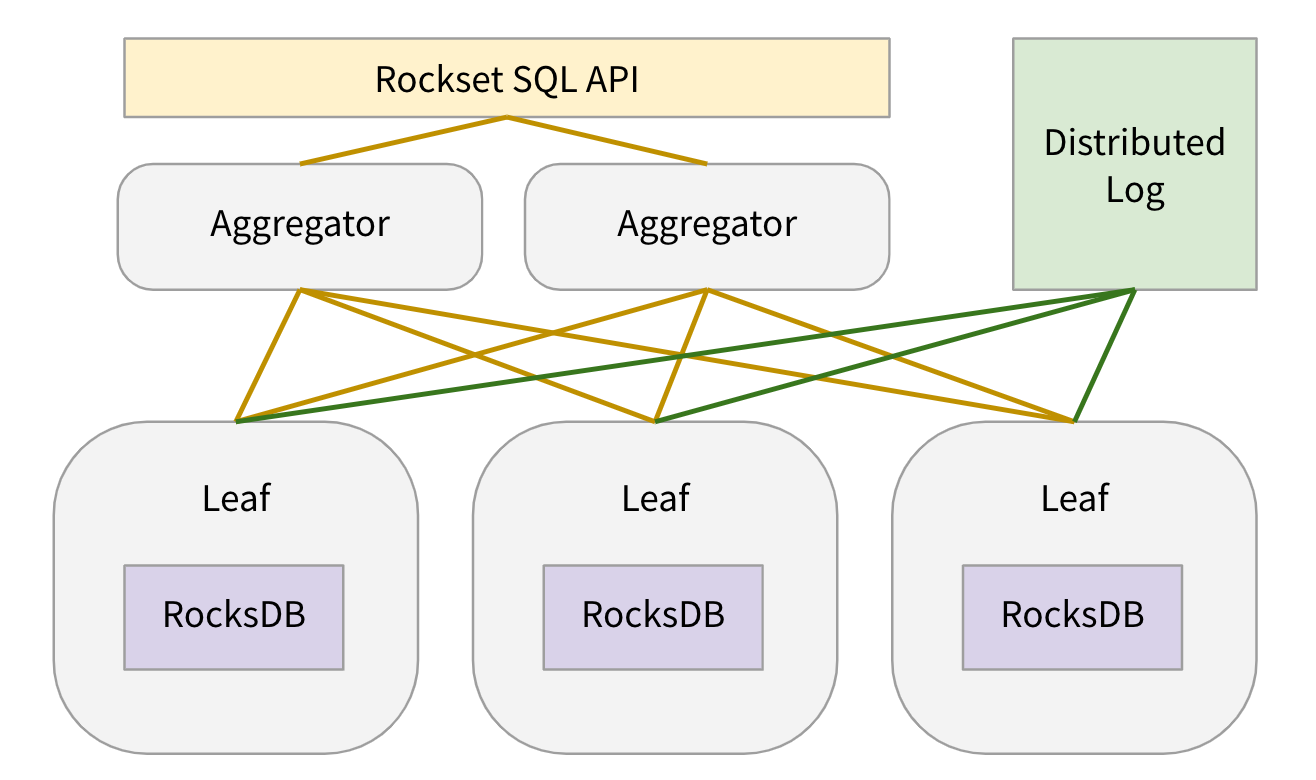
Let me quickly describe where the RocksDB storage nodes fall in the overall system architecture.

When a user creates a collection, we internally create N shards for the collection. Each shard is replicated k-ways (usually k=2) to achieve high read availability and each shard replica is assigned to a leaf node. Each leaf node is assigned many shard replicas of many collections. In our production environment each leaf node has around 100 shard replicas assigned to it. Leaf nodes create 1 RocksDB instance for each shard replica assigned to them. For each shard replica, leaf nodes continuously pull updates from a DistributedLogStore and apply the updates to the RocksDB instance. When a query is received, leaf nodes are assigned query plan fragments to serve data from some of the RocksDB instances assigned to them. For more details on leaf nodes, please refer to Aggregator Leaf Tailer blog post or Rockset white paper.
To achieve query latency of milliseconds under 1000s of qps of sustained query load per leaf node while continuously applying incoming updates, we spent a lot of time tuning our RocksDB instances. Below, we describe how we tuned RocksDB for our use case.
RocksDB-Cloud
RocksDB is an embedded key-value store. The data in 1 RocksDB instance is not replicated to other machines. RocksDB cannot recover from machine failures. To achieve durability, we built RocksDB-Cloud. RocksDB-Cloud replicates all the data and metadata for a RocksDB instance to S3. Thus, all SST files written by leaf nodes get replicated to S3. When a leaf node machine fails, all shard replicas on that machine get assigned to other leaf nodes. For each new shard replica assignment, a leaf node reads the RocksDB files for that shard from corresponding S3 bucket and picks up where the failed leaf node left off.
Disable Write Ahead Log
RocksDB writes all its updates to a write ahead log and to the active in-memory memtable. The write ahead log is used to recover data in the memtables in the event of process restart. In our case, all the incoming updates for a collection are first written to a DistributedLogStore. The DistributedLogStore itself acts as a write ahead log for the incoming updates. Also, we do not need to guarantee data consistency across queries. It is ok to lose the data in the memtables and re-fetch it from the DistributedLogStore on restarts. For this reason, we disable RocksDB’s write ahead log. This means that all our RocksDB writes happen in-memory.
Writer Rate Limit
As mentioned above, leaf nodes are responsible for both applying incoming updates and serving data for queries. We can tolerate relatively much higher latency for writes than for queries. As much as possible, we always want to use a fraction of available compute capacity for processing writes and most of compute capacity for serving queries. We limit the number of bytes that can be written per second to all RocksDB instances assigned to a leaf node. We also limit the number of threads used to apply writes to RocksDB instances. This helps minimize the impact RocksDB writes could have on query latency. Also, by throttling writes in this manner, we never end up with imbalanced LSM tree or trigger RocksDB’s built-in unpredictable back-pressure/stall mechanism. Note that both of these features are not available in RocksDB, but we implemented them on top of RocksDB. RocksDB supports a rate limiter to throttle writes to the storage device, but we need a mechanism to throttle writes from the application to RocksDB.
Sorted Write Batch
RocksDB can achieve higher write throughput if individual updates are batched in a WriteBatch and further if consecutive keys in a write batch are in a sorted order. We take advantage of both of these. We batch incoming updates into micro-batches of ~100KB size and sort them before writing them to RocksDB.
Dynamic Level Target Sizes
In an LSM tree with leveled compaction policy, files from a level do not get compacted with files from the next level until the target size of the current level is exceeded. And the target size for each level is computed based on the specified L1 target size and level size multiplier (usually 10). This usually results in higher space amplification than desired until the last level has reached its target size as described on RocksDB blog. To alleviate this, RocksDB can dynamically set target sizes for each level based on the current size of the last level. We use this feature to achieve the expected 1.111 space amplification with RocksDB regardless of the amount of data stored in the RocksDB instance. It can be turned on by setting AdvancedColumnFamilyOptions::level_compaction_dynamic_level_bytes to true.
Shared Block Cache
As mentioned above, leaf nodes are assigned many shard replicas of many collections and there is one RocksDB instance for each shard replica. Instead of using a separate block cache for each RocksDB instance, we use 1 global block cache for all RocksDB instances on the leaf node. This helps achieve better memory utilization by evicting unused blocks across all shard replicas out of leaf memory. We give block cache about 25% of the memory available on a leaf pod. We intentionally do not make block cache even bigger even if there is spare memory available that is not used for processing queries. This is because we want the operating system page cache to have that spare memory. Page cache stores compressed blocks while block cache stores uncompressed blocks, so page cache can more densely pack file blocks that are not so hot. As described in Optimizing Space Amplification in RocksDB paper, page cache helped reduce file system reads by 52% for three RocksDB deployments observed at Facebook. And page cache is shared by all containers on a machine, so the shared page cache serves all leaf containers running on a machine.
No Compression For L0 & L1
By design, L0 and L1 levels in an LSM tree contain very little data compared to other levels. There is little to be gained by compressing the data in these levels. But, we could save some cpu by not compressing data in these levels. Every L0 to L1 compaction needs to access all files in L1. Also, range scans cannot use bloom filter and need to look up all files in L0. Both of these frequent cpu-intensive operations would use less cpu if data in L0 and L1 does not need to be uncompressed when read or compressed when written. This is why, and as recommended by RocksDB team, we do not compress data in L0 and L1, and use LZ4 for all other levels.
Bloom Filters On Key Prefixes
As described in our blog post, Converged Index™: The Secret Sauce Behind Rockset’s Fast Queries, we store every column of every document in RocksDB multiple key ranges. For queries, we read each of these key ranges differently. Specifically, we do not ever look up a key in any of these key ranges using the exact key. We usually simply seek to a key using a smaller, shared prefix of the key. Therefore, we set BlockBasedTableOptions::whole_key_filtering to false so that whole keys are not used to populate and thereby pollute the bloom filters created for each SST. We also use a custom ColumnFamilyOptions::prefix_extractor so that only the useful prefix of the key is used for constructing the bloom filters.
Iterator Freepool
When reading data from RocksDB for processing queries, we need to create 1 or more rocksdb::Iterators. For queries that perform range scans or retrieve many fields, we need to create many iterators. Our cpu profile showed that creating these iterators is expensive. We use a freepool of these iterators and try to reuse iterators within a query. We cannot reuse iterators across queries as each iterator refers to a specific RocksDB snapshot and we use the same RocksDB snapshot for a query.
Finally, here is the full list of configuration parameters we specify for our RocksDB instances.
Options.max_background_flushes: 2
Options.max_background_compactions: 8
Options.avoid_flush_during_shutdown: 1
Options.compaction_readahead_size: 16384
ColumnFamilyOptions.comparator: leveldb.BytewiseComparator
ColumnFamilyOptions.table_factory: BlockBasedTable
BlockBasedTableOptions.checksum: kxxHash
BlockBasedTableOptions.block_size: 16384
BlockBasedTableOptions.filter_policy: rocksdb.BuiltinBloomFilter
BlockBasedTableOptions.whole_key_filtering: 0
BlockBasedTableOptions.format_version: 4
LRUCacheOptionsOptions.capacity : 8589934592
ColumnFamilyOptions.write_buffer_size: 134217728
ColumnFamilyOptions.compression[0]: NoCompression
ColumnFamilyOptions.compression[1]: NoCompression
ColumnFamilyOptions.compression[2]: LZ4
ColumnFamilyOptions.prefix_extractor: CustomPrefixExtractor
ColumnFamilyOptions.compression_opts.max_dict_bytes: 32768
Learn more about how Rockset uses RocksDB: