{kind=link}
MongoDB is the most popular NoSQL database today, by some measures, even taking on traditional SQL databases like MySQL, which have been the de facto standard for many years. MongoDB’s document model and flexible schemas allow for rapid iteration in applications. MongoDB is designed to scale out to massive datasets and workloads, so developers know they will not be limited by their database. MongoDB supports a variety of indexes, which accelerate selective queries in much the same way as a SQL database.
However, there comes a point in the lifetime of an application when a secondary index or replica of the production database is needed. As a NoSQL database, MongoDB is not built to perform for JOINs, and cannot run SQL queries. If you want to run analytical queries that aggregate a large amount of data, running them on the primary production database risks interrupting the performance of that database for application serving queries. A secondary database, designed for serving large analytic queries, can obviate that risk.
External Indexing Using Rockset
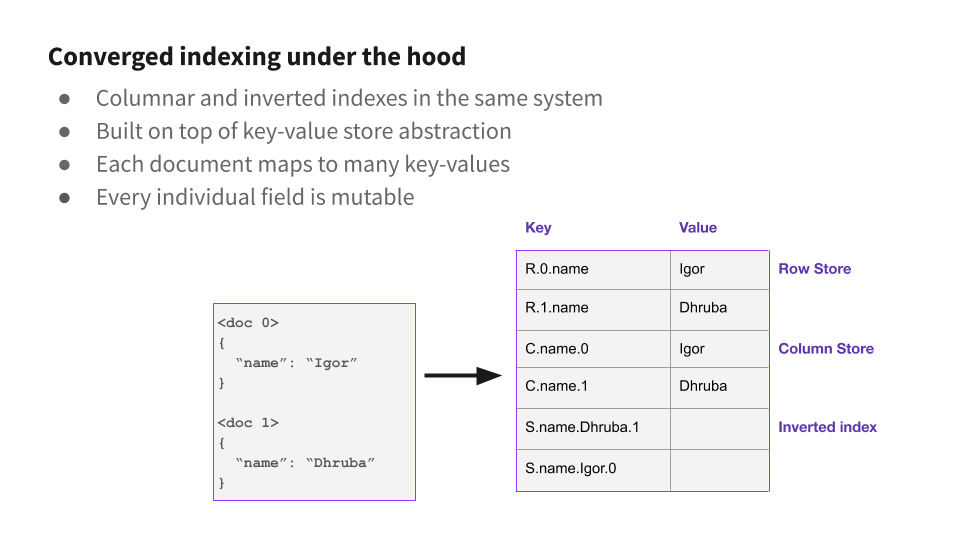
Rockset recently partnered with MongoDB to build an integration that allows Rockset to be used as an external indexing layer. Rockset uses Converged Indexing to accelerate queries with minimal configuration. Every document is indexed on every field, even nested fields inside arrays or objects. Rockset indexes every field automatically so users don’t need to build indexes to make queries fast — queries are indexed by default. There is no limit to the number of fields which can be ingested and indexed. Rockset’s Converged Index™ is the most efficient way to organize your data and enables queries to be available almost instantly and perform incredibly fast. It is designed to scale well for documents with thousands of fields or more.

Our unique approach to indexing often leaves people with questions. How do we maintain indexes on every field when documents can maintain thousands or even millions of fields? What sort of queries can take advantage of these indexes? By design, it isn’t necessary to understand Rockset’s indexing engine in order to use Rockset. However, it can be helpful to understand how Rockset indexes data, and how Rockset indexes compare to other systems, specifically indexing in MongoDB, when transitioning to Rockset.
Single Field Indexes
In MongoDB, you can create a single field index on a field to quickly select all documents with a particular value of a field, or a contiguous range of values.
Rockset indexes are very similar, but they are created automatically for every field, and there is no limit to the number of indexes you can have. When Rockset ingests a document, every scalar field is automatically added to an inverted index. This includes fields inside arrays or objects. For each field, we store a map from each value to the set of documents which contain that value. To evaluate a query with an equality predicate (say SELECT * FROM people WHERE name="Ben"), Rockset finds the inverted index entry for desired value (Ben), finds the documents which match and looks up all of the other fields for that document.
Compound Indexes
You can use compound indexes in MongoDB if you want to search a collection with constraints on two field simultaneously. Compound indexes are great for equality predicates and certain range predicates, but don’t support all combinations of predicates and sort orders.
Rockset uses a more flexible approach similar to MongoDB’s index intersection. For every field, we store the list of documents which contain each distinct value. If you have predicates on multiple fields, we retrieve the set of documents which match each predicate from the index, and take the intersection (AND) or the union (OR). While this approach requires minimal configuration and is fast for most queries, in some cases a true compound index can outperform index intersection. If Rockset users want the functionality of a compound index, they can specify a field mapping to combine the fields they want to index on to create a new field, and use an index on that combined field.
Rockset can intersect the result sets of different indexes efficiently because within each value, the documents are all sorted in the same order. Therefore we can intersect two sets in streaming fashion, which is both fast and memory efficient. For evaluating range predicates, we use a data structure called a static range tree. We group numeric values and timestamps into buckets at various levels of granularity so we can find documents with a range of values by combing a small number of distinct sets.
Multikey Indexes
MongoDB multikey indexes allow users to index values inside of arrays. This accelerates a query to find all documents where an array contains a value. For instance, if each user has a list of interests, you can use a multikey index to find all users who are interested in a given topic quickly.
Rockset automatically indexes every element of every array, so queries like SELECT * FROM people WHERE ARRAY_CONTAINS(interests, 'databases') are accelerated by an index with no configuration.
Text Indexes
Text indexes are useful for text search – finding all documents where a string contains a term or set of terms. MongoDB text index and Rockset text indexes are very similar. Strings are first broken down into tokens and normalized to the root word based on the language locale. then you can score strings based on how many search terms they contain.
Rockset text indexes are a little different from other indexes in that the user must do a little work to create them explicitly. Rockset text search operates on an array of strings (words) rather than a single string. Rockset will automatically perform this tokenization at ingest time if you set up an appropriate field mapping. Once your data is ingested, you can use the SEARCH function to use Rockset text search. This query will find all applicants whose resumes contain either the term “rockset” or “sql”, and show those that contain more matches first:
SELECT
*
FROM
applicants
WHERE
search(
has_term(resume, 'rockset'),
has_term(resume, 'sql')
)
ORDER BY
score() DESC
Wildcard Indexes
In MongoDB, a wildcard index creates an index on all nested paths inside an object. This is useful if the schema of the object is dynamic, and you want to automatically index new fields, or the object has many fields and you want to index all of them. Users create a wildcard index by running the following command:
db.collection.createIndex( { "field.$**" : 1 } )
At Rockset, we think indexing data automatically is a great idea, so we build indexes automatically on every field, even deeply nested fields inside objects. Rockset essentially has a wildcard index on the entire document. Unlike wildcard indexes in MongoDB, even nested geographical fields are indexed. While MongoDB restricts users to a total of 64 indexes, Rockset allows collections to have an unlimited number of indexes.
2dsphere Indexes
MongoDB and Rockset both support fast queries for geographical shapes – nearby points, points inside a polygon, etc. Any data which contains latitudes and longitudes can likely benefit from a geospatial index. In fact, both MongoDB and Rockset use the Google S2 library for storing and manipulating geographical objects. All you need to do to start using Rockset’s geospatial index is to ingest geographically typed data. For learn more about how Rockset geospatial indexes work and how you can use them, check out Outside Lands, Airbnb Prices, and Rockset’s Geospatial Queries.
2d and geoHaystack Indexes
MongoDB has 2dsphere indexes for indexing spherical geometry (i.e. the surface of the Earth) and 2d and geoHaystack indexes for indexing objects in flat, Euclidean geometry.
Unfortunately, Rockset does not support 2d indexes in Euclidean space. As a workaround, you can specify the two coordinates as separate fields, and write a query which uses both fields. For instance, if you want to find all (x, y) points near (1, 1), you could run the following query, and it would intersect the set of points with x in (0, 2) and y in (0, 2):
SELECT * FROM points WHERE x > 0 AND x < 2 AND y > 0 AND y < 2
Another option is to convert your points into latitude/longitude coordinates in a small range (say -1 to 1), and use Rockset’s geospatial index. While results won’t be exact due to the curvature of a sphere, within a small range the surface of a sphere approximates a plane.
Hashed Indexes
If you create a hashed index on a field x in MongoDB, it creates a mapping from the hash of x to all the documents which contain that value of x (a posting list). Hashed indexes are useful for equality predicates. Rockset’s inverted index is similar, in that we store a posting list for every distinct value, so it can be used to accelerate an equality predicate. The Rockset inverted index doesn’t hash the values though, so it can also be used to accelerate range predicates by merging the posting lists for all values in a range.
Hashed indexes in MongoDB can also be used to shard a collection based on a given hash key. Rockset does not allow users to control sharding. Instead, documents are automatically sharded evenly to ensure writes and reads are balanced across all replicas. This maximizes parallelism and performance.
Getting the Most Out of Rockset’s Indexes
Rockset is designed to minimize the amount of user configuration to get fast queries, but there are still steps you can take to make your queries faster. You can run EXPLAIN on the query in question to see how the query is being executed. If you see index filter, the query is being accelerated by one or more indexes.
api.rs2.usw2.rockset.com> EXPLAIN SELECT * from people WHERE age > 18;
+----------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
|----------------------------------------------------------------------------------------------------------------|
| select *:$2 |
| reshuffle on_final |
| index filter on commons.people: fields($2=*, $1=age), query($1:float(18,inf], int(18,9223372036854775807]) |
+----------------------------------------------------------------------------------------------------------------+
Here are a few common reasons your query may not use an index:
- If you’re searching by a LIKE pattern or regular expression with a wildcard at the beginning (i.e.,
WHERE haystack LIKE %needle%), we cannot use an index. If you are searching for a particular word or token, you should try creating a text index with a field mapping, and use text search instead of LIKE. - A query which selects documents based on the output of a function (i.e.
WHERE DATE_PARSE(creation_date, '%Y/%m/%d') = DATE(2020, 7, 13)) Rockset cannot apply the index. You can either rewrite the predicate to apply directly to a field (WHERE creation_date="2020/07/13") or create a field mapping with the output of the function, then apply a predicate on that. - Where possible, express predicates as ranges. For instance, if you want to find all strings which start with an upper case letter, use
WHERE my_string >= 'A' AND my_string <= '['rather thanWHERE UPPER(SUBSTR(my_string, 1, 1)) = SUBSTR(my_string, 1, 1).
You can find more advice on accelerating your queries in the query performance guide.
Other MongoDB resources: