{kind=link}
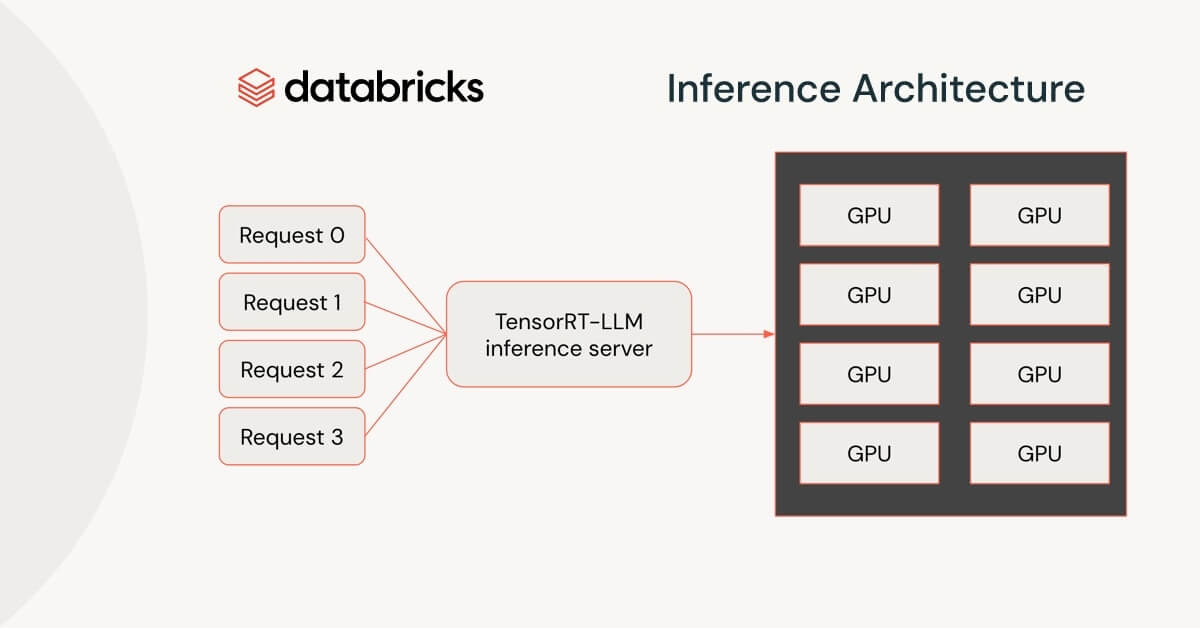
The Databricks / Mosaic R&D team launched the first iteration of our inference service architecture only seven months ago; since then, we’ve been making tremendous strides in delivering a scalable, modular, and performant platform that is ready to integrate every new advance in the fast-growing generative AI landscape. In January 2024, we will start using a new inference engine for serving Large Language Models (LLMs), built on NVIDIA TensorRT-LLM.
Introducing NVIDIA TensorRT-LLM
TensorRT-LLM is an open source library for state-of-the-art LLM inference. It consists of several components: first-class integration with NVIDIA’s TensorRT deep learning compiler, optimized kernels for key operations in language models, and communication primitives to enable efficient multi-GPU serving. These optimizations seamlessly work on inference services powered by NVIDIA Tensor Core GPUs and are a key part of how we deliver state-of-the-art performance.
For the last six months, we’ve been collaborating with NVIDIA to integrate TensorRT-LLM with our inference service, and we are excited about what we’ve been able to accomplish. Using TensorRT-LLM, we are able to deliver a significant improvement in both time to first token and time per output token. As we discussed in an earlier post, these metrics are key estimators for the quality of the user experience when working with LLMs.
Our collaboration with NVIDIA has been mutually advantageous. During the early access phase of the TensorRT-LLM project, our team contributed MPT model conversion scripts, making it faster and easier to serve an MPT model directly from Hugging Face, or your own pre-trained or fine-tuned model using the MPT architecture. In turn, NVIDIA ’s team augmented MPT model support by adding installation instructions, as well as introducing quantization and FP8 support on H100 Tensor Core GPUs. We’re thrilled to have first-class support for the MPT architecture in TensorRT-LLM, as this collaboration not only benefits our team and customers, but also empowers the broader community to freely adapt MPT models for their specific needs with state-of-the-art inference performance.
Flexibility Through Plugins
Extending TensorRT-LLM with newer model architectures has been a smooth process. The inherent flexibility of TensorRT-LLM and its ability to add different optimizations through plugins enabled our engineers to quickly modify it to support our unique modeling needs. This flexibility has not only accelerated our development process but also alleviated the need for the NVIDIA team to single-handedly support all user requirements.
A Critical Component for LLM Inference
We’ve conducted comprehensive benchmarks of TensorRT-LLM across all GPU models (A10G, A100, H100) on each cloud platform. To achieve optimal latency at minimal cost, we’ve optimized the TensorRT-LLM configuration such as continuous batch sizes, tensor sharding, and model pipelining which we have covered earlier. We’ve deployed the optimal configuration for top LLM models including LLAMA-2 and Mixtral for each cloud and instance configuration and will continue to do so as new models and hardware are released. You can always get the best LLM performance out of the box with Databricks model serving!
Python API for Easier Integration
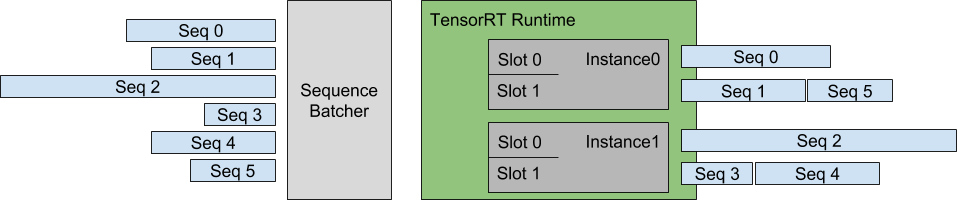
TensorRT-LLM’s offline inference performance becomes more powerful when used in tandem with its native in-flight (continuous) batching support. We’ve found that in-flight batching is a crucial component of maintaining high request throughput in settings with lots of traffic. Recently, the NVIDIA team has been working on Python support for the batch manager written in C++, allowing TensorRT-LLM to be seamlessly integrated into our backend web server.
Ready to Begin Experimenting?
If you’re a Databricks customer, you can use our inference server via our AI Playground (currently in public preview) today. Just log in and find the Playground item in the left navigation bar under Machine Learning.
We want to thank the team at NVIDIA for being terrific collaborators as we’ve worked through the journey of integrating TensorRT-LLM as the inference engine for hosting LLMs. We’re going to be leveraging TensorRT-LLM as a basis for our innovations in the upcoming releases of the Databricks Inference Engine. We’re looking forward to sharing our platform’s performance improvements over previous implementations. (It’s also important to note that vLLM, a large open-source community effort for efficient LLM inference, provides another great option and is gaining momentum.) Stay tuned for an upcoming blog post with a deeper dive into the performance details next month.